Dr. Dmitry Ryumin

 Community Services
Community Services
Journal Reviewing
Conference Reviewing
![]()
![]()
![]()
![]()
 Latest posts
Latest posts
| Jul 16, 2024 | Introduction to Datasets |
|---|---|
| Jul 05, 2024 | Introduction to Deep Learning |
 Selected Publications
Selected Publications
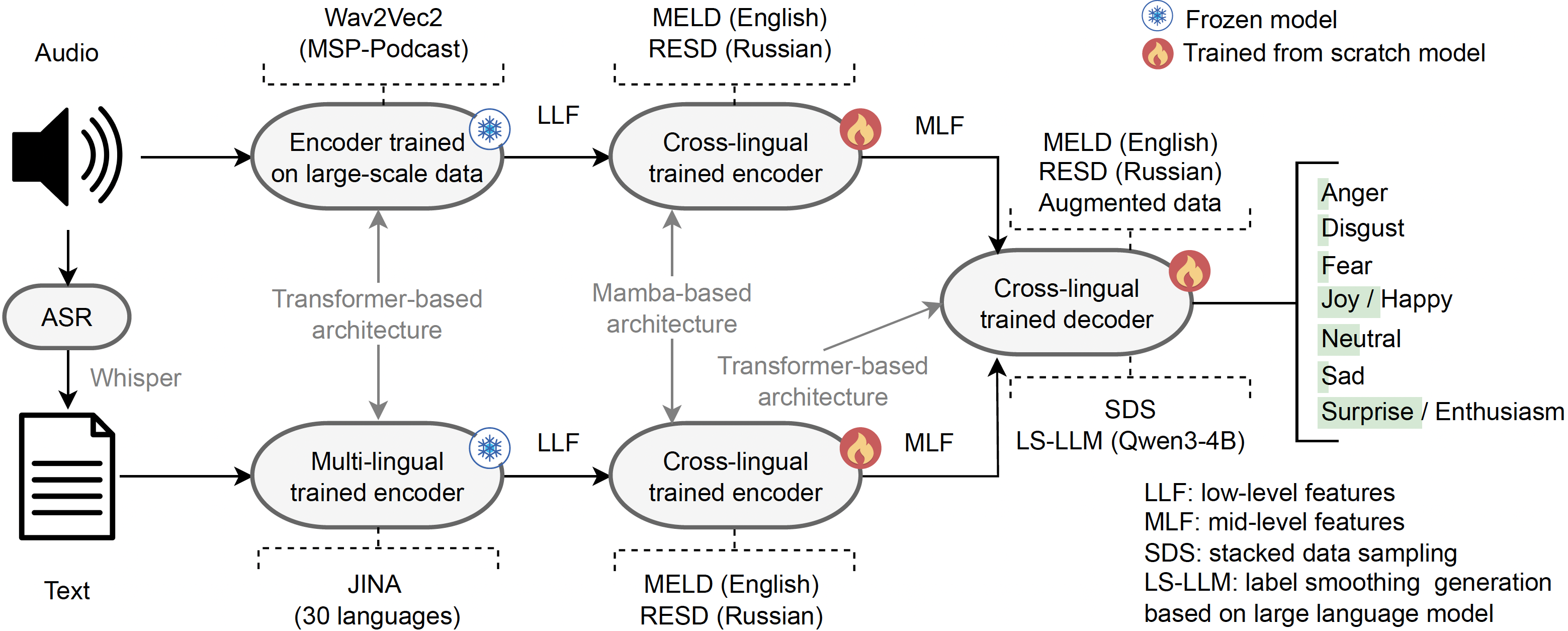
- Cross-Lingual Bimodal Emotion Recognition with LLM-based Label SmoothingBig Data and Cognitive Computing, 2025
Bimodal emotion recognition based on audio and text is widely adopted in video-constrained real-world applications such as call centers and voice assistants. However, existing systems suffer from limited cross-domain generalization and monolingual bias. To address these limitations, a cross-lingual bimodal emotion recognition method is proposed, integrating Mamba-based temporal encoders for audio (Wav2Vec2.0) and text (Jina-v3) with a Transformer-based cross-modal fusion architecture (BiFormer). Three corpus-adaptive augmentation strategies are introduced: (1) Stacked Data Sampling, in which short utterances are concatenated to stabilize sequence length; (2) Label Smoothing Generation based on Large Language Model, where the Qwen3-4B model is prompted to detect subtle emotional cues missed by annotators, producing soft labels that reflect latent emotional co-occurrences; and (3) Text-to-Utterance Generation, in which emotionally labeled utterances are generated by ChatGPT-5 and synthesized into speech using the DIA-TTS model, enabling controlled creation of affective audio–text pairs without human annotation. BiFormer is trained jointly on the English Multimodal EmotionLines Dataset and the Russian Emotional Speech Dialogs corpus, enabling cross-lingual transfer without parallel data. Experimental results show that the optimal data augmentation strategy is corpus-dependent: Stacked Data Sampling achieves the best performance on short, noisy English utterances, while Label Smoothing Generation based on Large Language Model better captures nuanced emotional expressions in longer Russian utterances. Text-to-Utterance Generation does not yield a measurable gain due to current limitations in expressive speech synthesis. When combined, the two best performing strategies produce complementary improvements, establishing new state-of-the-art performance in both monolingual and cross-lingual settings.
@article{ryumina25_bdcc, author = {Ryumina, Elena and Axyonov, Alexandr and Abdulkadirov, Timur and Koryakovskaya, Darya and Ryumin, Dmitry}, title = {{Cross-Lingual Bimodal Emotion Recognition with LLM-based Label Smoothing}}, volume = {9}, pages = {1--38}, journal = {Big Data and Cognitive Computing}, year = {2025}, issn = {2504-2289}, doi = {10.3390/bdcc9110285}, url = {https://www.mdpi.com/2504-2289/9/11/285}, keywords = {Bimodal Emotion Recognition, Cross-Lingual Modeling, Cross-Modal Attention, Large Language Model, Mamba Architecture, Stacked Data Sampling, Template-based Utterance Generation, Label Smoothing Generation}, } - ICCVW
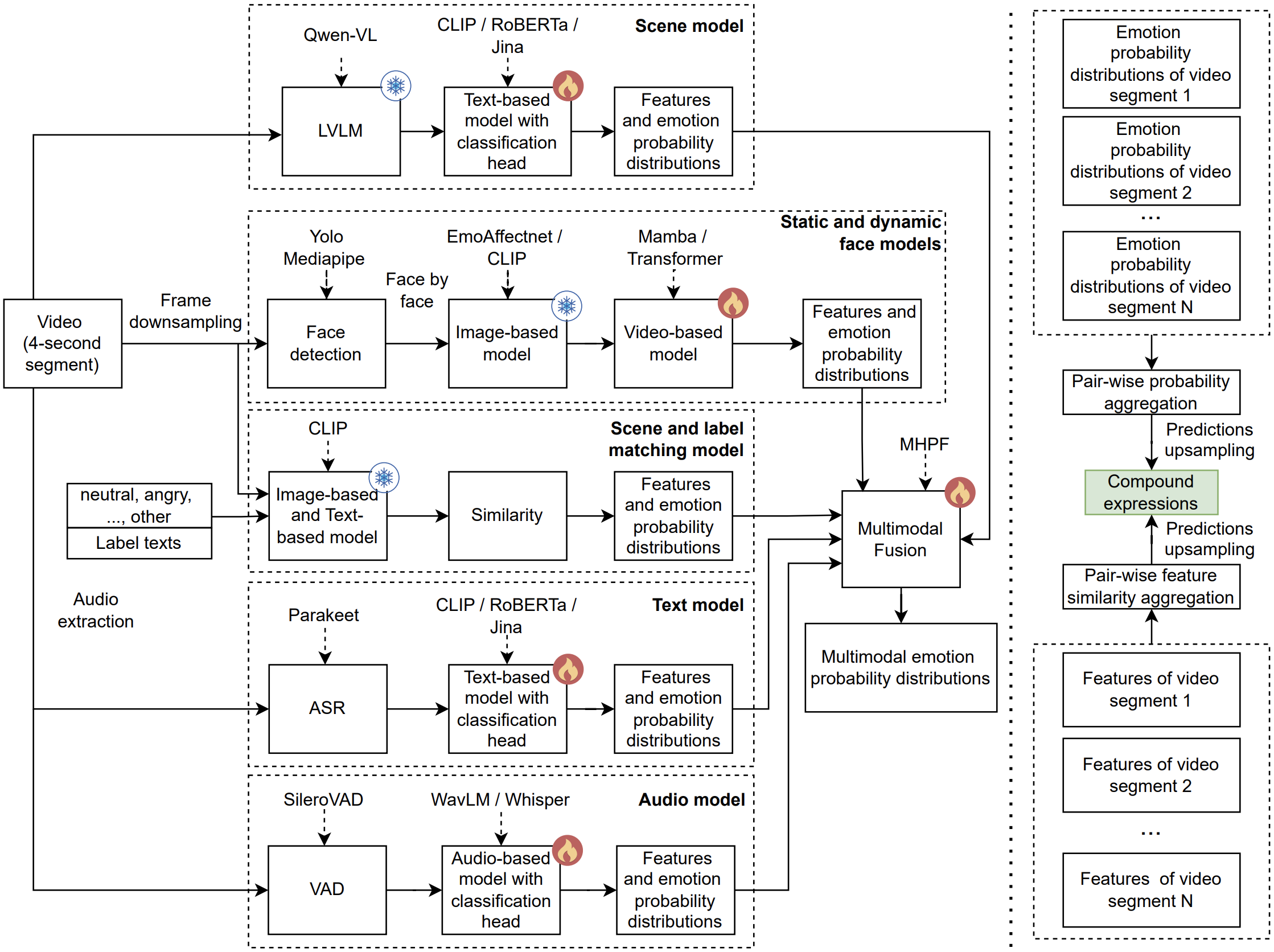 Zero-Shot Multimodal Compound Expression Recognition Approach using Off-the-Shelf Large Visual-Language ModelsElena Ryumina, Maxim Markitantov, Alexandr Axyonov, Dmitry Ryumin, Mikhail Dolgushin, and 1 more authorIn Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2025
Zero-Shot Multimodal Compound Expression Recognition Approach using Off-the-Shelf Large Visual-Language ModelsElena Ryumina, Maxim Markitantov, Alexandr Axyonov, Dmitry Ryumin, Mikhail Dolgushin, and 1 more authorIn Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), 2025Compound Expression Recognition (CER), a subfield of affective computing, aims to detect complex emotional states formed by combinations of basic emotions. In this work, we present a novel zero-shot multimodal approach for CER that combines six heterogeneous modalities into a single pipeline: static and dynamic facial expressions, scene and label matching, scene context, audio, and text. Unlike previous approaches relying on task-specific training data, our approach uses zero-shot components, including Contrastive Language-Image Pretraining (CLIP)-based label matching and Qwen-VL for semantic scene understanding. We further introduce a Multi-Head Probability Fusion (MHPF) module that dynamically weights modality-specific predictions, followed by basic-to-compound emotion conversion that uses Pair-wise Probability Aggregation (PPA) or Pair-wise Feature Similarity Aggregation (PFSA) methods to produce interpretable compound emotion outputs. Evaluated under multi-corpus training, the proposed approach achieves macro-F1 scores of 46.95% on AffWild2, 49.02% on Acted Facial Expressions in The Wild (AFEW), and 34.85% on C-EXPR-DB via zero-shot testing, comparable to supervised approaches trained on target data. Thus our approach effectively captures Compound Expressions (CE) without domain adaptation.
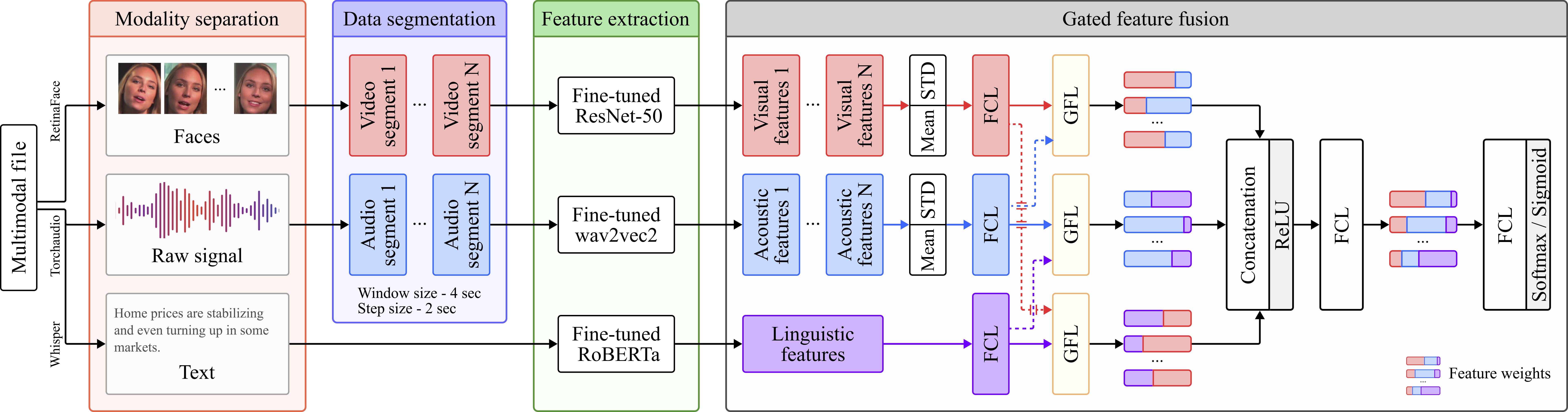
@inproceedings{ryumina25_iccvw, author = {Ryumina, Elena and Markitantov, Maxim and Axyonov, Alexandr and Ryumin, Dmitry and Dolgushin, Mikhail and Karpov, Alexey}, title = {{Zero-Shot Multimodal Compound Expression Recognition Approach using Off-the-Shelf Large Visual-Language Models}}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)}, year = {2025}, pages = {71--79}, url = {https://openaccess.thecvf.com/content/ICCV2025W/ABAW/html/Ryumina_Zero-Shot_Multimodal_Compound_Expression_Recognition_Approach_using_Off-the-Shelf_Large_Visual-Language_ICCVW_2025_paper.html}, dimensions = {true}, } - Multi-Corpus Emotion Recognition Method based on Cross-Modal Gated Attention FusionPattern Recognition Letters, 2025
Automatic emotion recognition techniques are critical to natural human–computer interaction. However, current methods suffer from limited applicability due to their tendency to overfit on single-corpus datasets. It reduces real-world effectiveness of the methods when faced with new unseen corpora. We propose the first multi-corpus multimodal emotion recognition method with high generalizability evaluated through a leave-one-corpus-out protocol. The method uses three fine-tuned encoders per modality (audio, video, and text) and a decoder employing a context-independent gated attention to combine features from all three modalities. The research is conducted on four benchmark corpora: MOSEI, MELD, IEMOCAP, and AFEW. The proposed method achieves the state-of-the-art results on these corpora and establishes the first baseline for multi-corpus studies. We demonstrate that due to the MELD rich emotional expressiveness across three modalities, the models trained on it exhibit the best generalization ability when applied to other corpora used. We also reveal that the AFEW annotation better correlates with the annotations of MOSEI, MELD, and IEMOCAP, as well as shows the best cross-corpus performance as it is consistent with the widely-accepted theories of basic emotions.
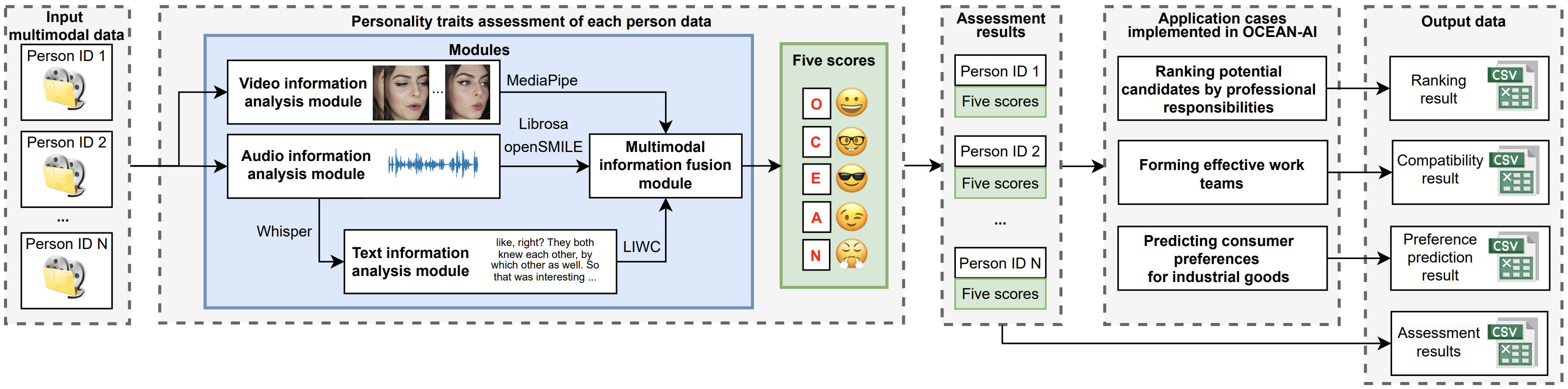
@article{ryumina25_prl, author = {Ryumina, Elena and Ryumin, Dmitry and Axyonov, Alexandr and Ivanko, Denis and Karpov, Alexey}, title = {{Multi-Corpus Emotion Recognition Method based on Cross-Modal Gated Attention Fusion}}, volume = {190}, pages = {192--200}, journal = {Pattern Recognition Letters}, year = {2025}, issn = {0167-8655}, doi = {10.1016/j.patrec.2025.02.024}, url = {https://www.sciencedirect.com/science/article/pii/S0167865525000662}, keywords = {Multimodal Emotion Recognition, Encoders-Decoder, Context-Independent Features, Gated Feature Fusion, Multi-Corpus Study, Affective Computing}, } - OCEAN-AI: Open Multimodal Framework for Personality Traits Assessment and HR-Processes AutomatizationElena Ryumina, Dmitry Ryumin, and Alexey KarpovIn Proceedings of the ISCA International Conference INTERSPEECH, 2024
Human personality traits (PT) reflect individual differences in patterns of thinking, feeling, and behaving. Knowledge on PT may be useful in many applied tasks in our everyday live. In this paper, we present a first open-source multimodal framework called OCEAN-AI for PT assessment (PTA) and HR-processes automatization. Our framework performs PTA analyzing three modalities, including audio, video, and text, and includes three processing modules. All the modules extract heterogeneous (deep neural and hand-crafted) features and use them for a com- plex analysis of human’s behavior. The final fourth module aggregates these six feature sets by a Siamese neural network with a gated attention mechanism. Our framework was tested on two free-available corpora, including First Impressions v2 and our MuPTA, and achieved the best results. Applying our framework, a user can automate solutions of some practical applied tasks, such as ranking potential candidates by professional responsibilities, forming efficient work teams and so on.
@inproceedings{ryumina24_interspeech, author = {Ryumina, Elena and Ryumin, Dmitry and Karpov, Alexey}, title = {{OCEAN-AI: Open Multimodal Framework for Personality Traits Assessment and HR-Processes Automatization}}, booktitle = {Proceedings of the ISCA International Conference INTERSPEECH}, year = {2024}, pages = {3630--3631}, url = {https://www.isca-archive.org/interspeech_2024/ryumina24_interspeech.html}, keywords = {Multimodal Paralinguistics, Analysis of Speaker Traits, Personality Traits Assessment, Multimodal System}, dimensions = {true}, } - Gated Siamese Fusion Network based on Multimodal Deep and Hand-Crafted Features for Personality Traits AssessmentPattern Recognition Letters, 2024
People tend to judge others assessing their personality traits relying on life experience. This fact is especially evident when making an informed hiring decision, which should consider not only skills, but also match a company’s values and culture. Based on this assumption, we use the Siamese Network (SN) for assessing five personality traits by pairwise analyzing and comparing people simultaneously. For this, we propose the OCEAN-AI framework based on Gated Siamese Fusion Network (GSFN), which comprises six modules and enables the fusion of hand-crafted and deep features across three modalities (video, audio, and text). We use the ChaLearn First Impressions v2 (FIv2) and Multimodal Personality Traits Assessment (MuPTA) corpora and identify that all six feature sets and their combinations due to different information content allow the framework to adjust to heterogeneous input data flexibly. The experimental results show that the pairwise comparison of people with the same or different Personality Traits (PT) during the training enhances the proposed framework performance. The framework outperforms the State-of-the-Art (SOTA) systems based on three modalities (video-face, audio and text) by the relative value of 1.3% (0.928 vs. 0.916) in terms of the mean accuracy (mACC) on the FIv2 corpus. We also outperform the SOTA system in terms of the Concordance Correlation Coefficient (CCC) by the relative value of 8.6% (0.667 vs. 0.614) using two modalities (video and audio) on the MuPTA corpus. We make our framework publicly available to integrate it into various applications such as recruitment, education, and healthcare.
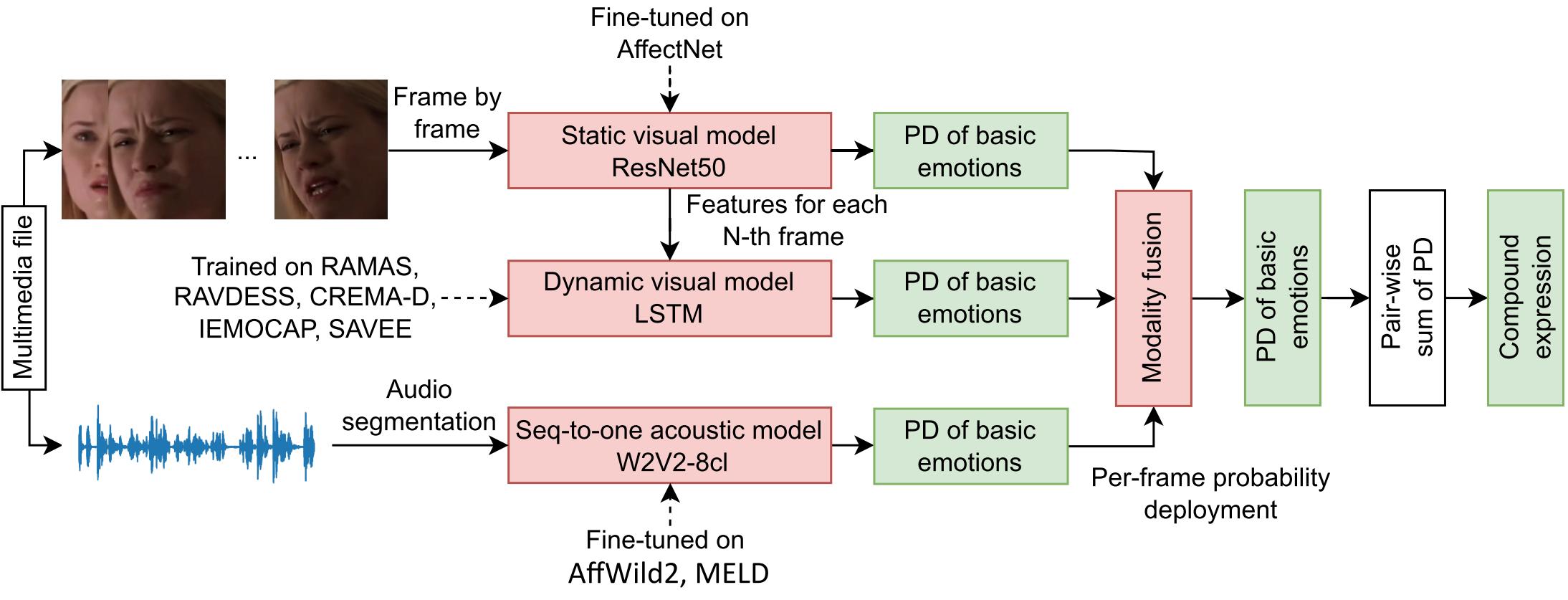
@article{ryumina24_prl, author = {Ryumina, Elena and Markitantov, Maxim and Ryumin, Dmitry and Karpov, Alexey}, title = {{Gated Siamese Fusion Network based on Multimodal Deep and Hand-Crafted Features for Personality Traits Assessment}}, volume = {185}, pages = {45--51}, journal = {Pattern Recognition Letters}, year = {2024}, issn = {0167-8655}, doi = {10.1016/j.patrec.2024.07.004}, url = {https://www.sciencedirect.com/science/article/pii/S0167865524002071}, keywords = {Deep Learning, Multimodal Paralinguistics, Multimodal Gated Fusion, Hand-Crafted and Deep Features, Personality Computing, Affective Computing}, } - Zero-Shot Audio-Visual Compound Expression Recognition Method based on Emotion Probability FusionIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2024
A Compound Expression Recognition (CER) as a subfield of affective computing is a novel task in intelligent human-computer interaction and multimodal user interfaces. We propose a novel audio-visual method for CER. Our method relies on emotion recognition models that fuse modalities at the emotion probability level while decisions regarding the prediction of compound expressions are based on the pair-wise sum of weighted emotion probability distributions. Notably our method does not use any training data specific to the target task. Thus the problem is a zero-shot classification task. The method is evaluated in multi-corpus training and cross-corpus validation setups. We achieved F1 scores of 32.15% and 25.56% for the AffWild2 and C-EXPR-DB test subsets without training on target corpus and target task respectively. Therefore our method is on par with methods developed training target corpus or target task.
@inproceedings{ryumina24_cvprw, author = {Ryumina, Elena and Markitantov, Maxim and Ryumin, Dmitry and Kaya, Heysem and Karpov, Alexey}, title = {{Zero-Shot Audio-Visual Compound Expression Recognition Method based on Emotion Probability Fusion}}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)}, year = {2024}, pages = {4752--4760}, url = {https://openaccess.thecvf.com/content/CVPR2024W/ABAW/html/Ryumina_Zero-Shot_Audio-Visual_Compound_Expression_Recognition_Method_based_on_Emotion_Probability_CVPRW_2024_paper.html}, dimensions = {true}, } - Audio-Visual Speech Recognition based on Regulated Transformer and Spatio-Temporal Fusion Strategy for Driver Assistive SystemsExpert Systems with Applications, 2024
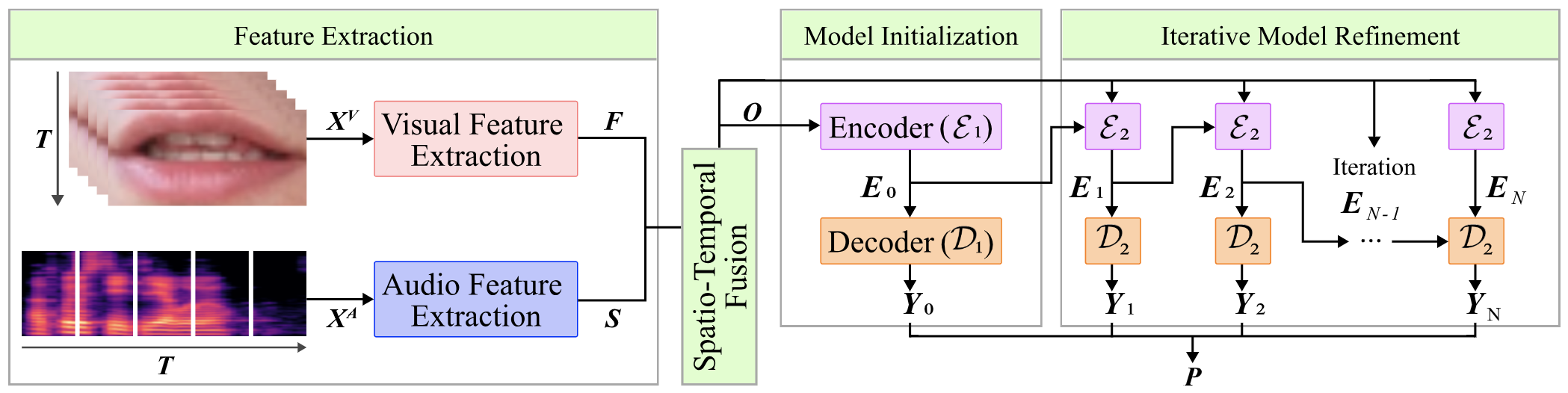
This article presents a research methodology for audio-visual speech recognition (AVSR) in driver assistive systems. These systems necessitate ongoing interaction with drivers while driving through voice control for safety reasons. The article introduces a novel audio-visual speech command recognition transformer (AVCRFormer) specifically designed for robust AVSR. We propose (i) a multimodal fusion strategy based on spatio-temporal fusion of audio and video feature matrices, (ii) a regulated transformer based on iterative model refinement module with multiple encoders, (iii) a classifier ensemble strategy based on multiple decoders. The spatio-temporal fusion strategy preserves contextual information of both modalities and achieves their synchronization. An iterative model refinement module can bridge the gap between acoustic and visual data by leveraging their impact on speech recognition accuracy. The proposed multi-prediction strategy demonstrates superior performance compared to traditional single-prediction strategy, showcasing the model’s adaptability across diverse audio-visual contexts. The transformer proposed has achieved the highest values of speech command recognition accuracy, reaching 98.87% and 98.81% on the RUSAVIC and LRW corpora, respectively. This research has significant implications for advancing human–computer interaction. The capabilities of AVCRFormer extend beyond AVSR, making it a valuable contribution to the intersection of audio-visual processing and artificial intelligence.
@article{Ruimin2024AVCRFormer, author = {Ryumin, Dmitry and Axyonov, Alexandr and Ryumina, Elena and Ivanko, Denis and Kashevnik, Alexey and Karpov, Alexey}, title = {{Audio-Visual Speech Recognition based on Regulated Transformer and Spatio-Temporal Fusion Strategy for Driver Assistive Systems}}, journal = {Expert Systems with Applications}, pages = {124159}, year = {2024}, doi = {10.1016/j.eswa.2024.124159}, url = {https://www.sciencedirect.com/science/article/pii/S095741742401025X}, keywords = {Audio-Visual Speech Recognition, Spatio-Temporal Fusion Strategy, Classifier Ensemble, Transformer, Computer Vision, Driver Assistive Systems}, dimensions = {true}, } - OCEAN-AI Framework with EmoFormer Cross-Hemiface Attention Approach for Personality Traits AssessmentExpert Systems with Applications, 2024
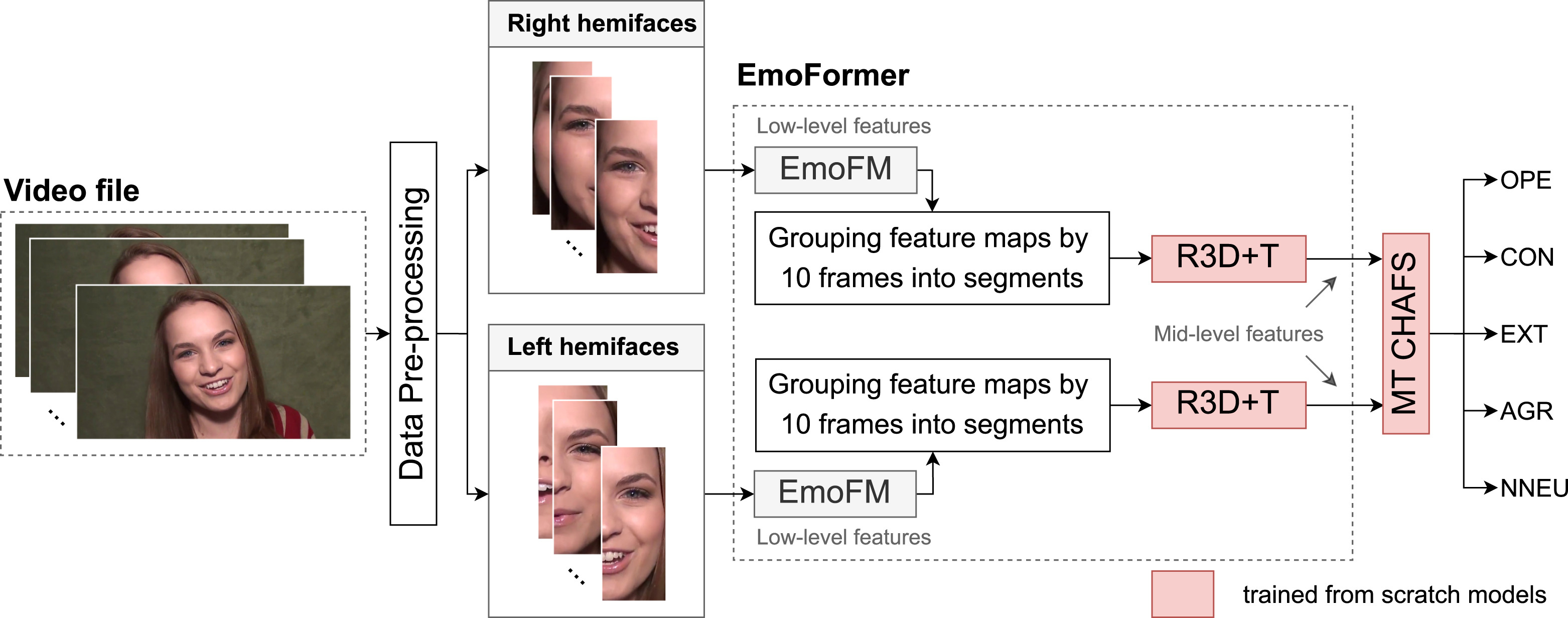
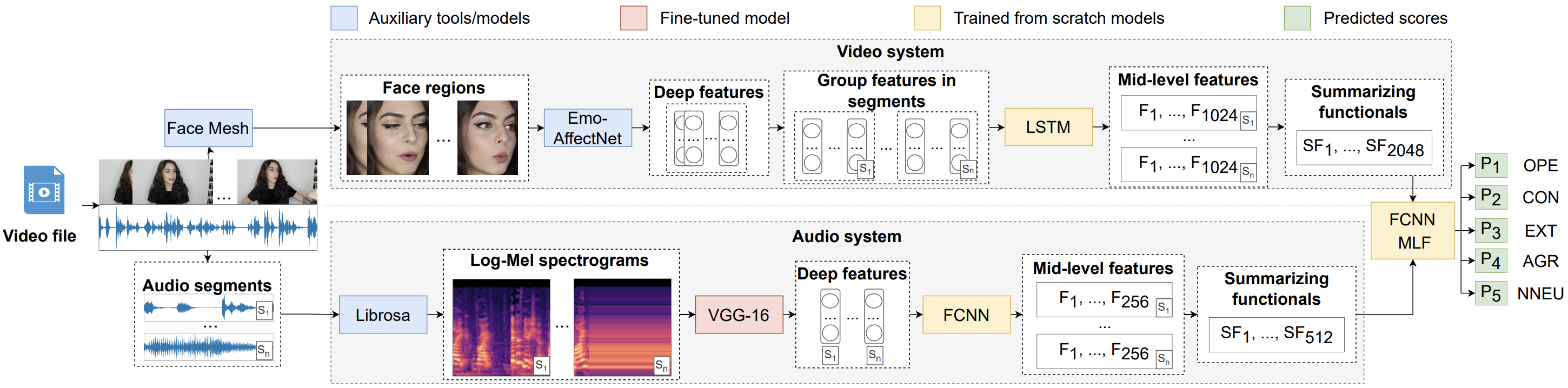
Psychological and neurological studies earlier suggested that a personality type can be determined by the whole face as well as by its sides. This article discusses novel research using deep neural networks that address the features of both sides of the face (hemifaces) to assess the human’s Big Five personality traits (PT). For this, we have developed a real-time approach called EmoFormer with cross-hemiface attention. The novelty of the presented approach lies in the confirmation that each hemiface exhibits high predictive capabilities in terms of human’s PT distinction. Our approach is based on a novel mid-level emotional feature extractor for each hemiface and a cross-hemiface attention fusion strategy for hemiface feature aggregation. The consequent fusion of both hemifaces has outperformed the use of the whole face by the relative value of 3.6% in terms of Concordance Correlation Coefficient (0.634 vs. 0.612) on the ChaLearn First Impressions V2 corpus. The proposed approach has also outperformed all the existing state-of-the-art approaches for PT assessment based on the face modality. We have also analyzed the “best hemiface”, the one that predicts PT more accurately in terms of demographic characteristics (gender, ethnicity, and age). We have found that the best hemiface for two of the five PT (Openness to experience and Non-Neuroticism) is different depending on demographic characteristics. For the other three traits, the right hemiface is dominant for Extraversion, while the left one is more indicative of Conscientiousness and Agreeableness. These findings support previous psychological and neurological research. Besides, we provide an open-source framework referred to as OCEAN-AI that can be seamlessly integrated into expert systems with practical applications in various domains including healthcare, education, and human resources.
@article{Ruimina2024OCEAN-AI, author = {Ryumina, Elena and Markitantov, Maxim and Ryumin, Dmitry and Karpov, Alexey}, title = {{OCEAN-AI Framework with EmoFormer Cross-Hemiface Attention Approach for Personality Traits Assessment}}, journal = {Expert Systems with Applications}, volume = {239}, pages = {122441}, year = {2024}, issn = {0957-4174}, doi = {10.1016/j.eswa.2023.122441}, url = {https://www.sciencedirect.com/science/article/pii/S0957417423029433}, keywords = {Personality Computing, Big Five, Emotional Features, Hemifaces, Feature-Level Fusion, Deep Learning, Transformer}, dimensions = {true}, } - Audio-Visual Speech Recognition In-the-Wild: Multi-Angle Vehicle Cabin Corpus and Attention-based MethodIn Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024
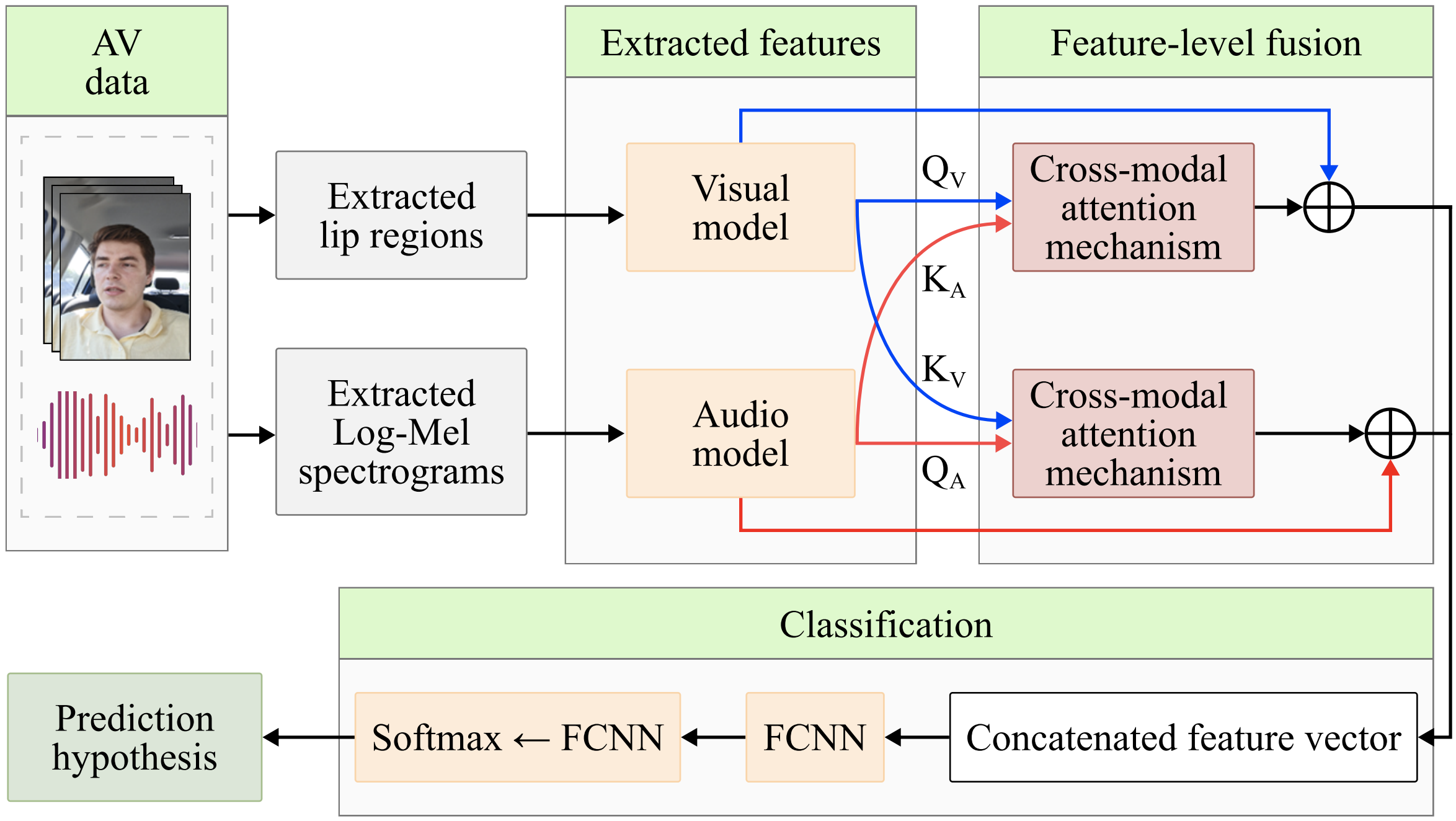
Audio-visual speech recognition (AVSR) gains increasing attention as an important part of human-machine interaction. However, the publicly available corpora are limited, particularly in driving conditions with prevalent background noise. Research so far has been collected in constrained environments, and thus cannot reflect the true performance of AVSR systems in real-world scenarios. Moreover, data for languages other than English is often unavailable. To meet the request for research on AVSR in unconstrained driving conditions, this paper presents a corpus collected ‘in-the-wild’. We propose a cross-modal attention method enhancing multi-angle AVSR for vehicles, leveraging visual context to improve accuracy and noise robustness. Our proposed model achieves state-of-the-art (SOTA) results with 98.65% accuracy in recognizing driver voice commands.
@inproceedings{axyonov24_icassp, author = {Axyonov, Alexandr and Ryumin, Dmitry and Ivanko, Denis and Kashevnik, Alexey and Karpov, Alexey}, title = {{Audio-Visual Speech Recognition In-the-Wild: Multi-Angle Vehicle Cabin Corpus and Attention-based Method}}, booktitle = {Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, year = {2024}, issn = {2379-190X}, pages = {8195--8199}, doi = {10.1109/ICASSP48485.2024.10448048}, url = {https://ieeexplore.ieee.org/document/10448048}, keywords = {Human Computer Interaction, Visualization, Speech Recognition, Signal Processing,Benchmark Testing, Noise Robustness, Noise Measurement, Multi-Modal Signal Processing,Audio-Visual Speech Recognition, Attention Mechanism, Feature-Level Fusion, Spatio-Temporal Features}, dimensions = {true}, } - Audio-Visual Speech and Gesture Recognition by Sensors of Mobile DevicesDmitry Ryumin *†, Denis Ivanko, and Elena Ryumina †Sensors, 2023
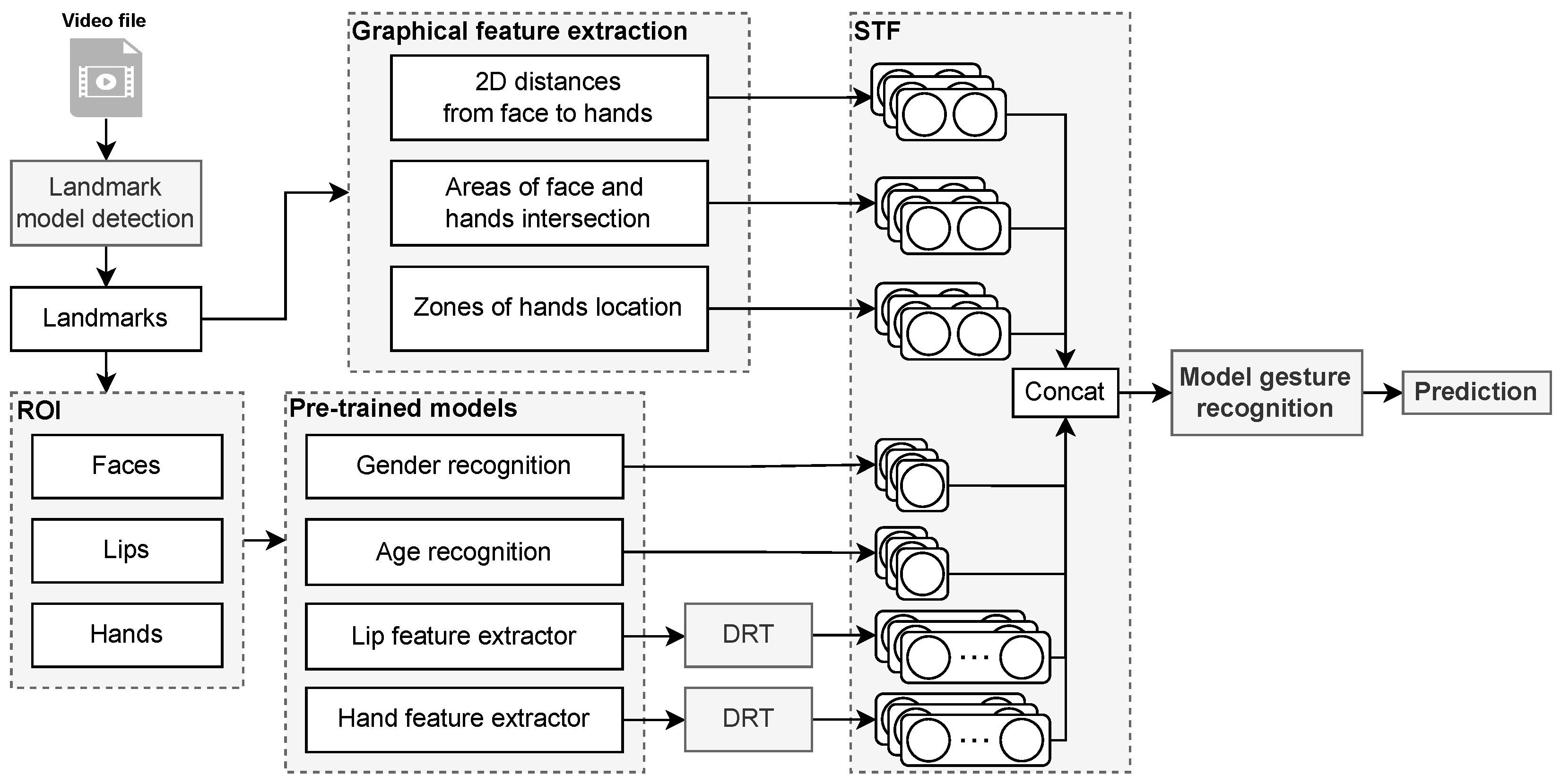
Audio-visual speech recognition (AVSR) is one of the most promising solutions for reliable speech recognition, particularly when audio is corrupted by noise. Additional visual information can be used for both automatic lip-reading and gesture recognition. Hand gestures are a form of non-verbal communication and can be used as a very important part of modern human–computer interaction systems. Currently, audio and video modalities are easily accessible by sensors of mobile devices. However, there is no out-of-the-box solution for automatic audio-visual speech and gesture recognition. This study introduces two deep neural network-based model architectures: one for AVSR and one for gesture recognition. The main novelty regarding audio-visual speech recognition lies in fine-tuning strategies for both visual and acoustic features and in the proposed end-to-end model, which considers three modality fusion approaches: prediction-level, feature-level, and model-level. The main novelty in gesture recognition lies in a unique set of spatio-temporal features, including those that consider lip articulation information. As there are no available datasets for the combined task, we evaluated our methods on two different large-scale corpora—LRW and AUTSL—and outperformed existing methods on both audio-visual speech recognition and gesture recognition tasks. We achieved AVSR accuracy for the LRW dataset equal to 98.76% and gesture recognition rate for the AUTSL dataset equal to 98.56%. The results obtained demonstrate not only the high performance of the proposed methodology, but also the fundamental possibility of recognizing audio-visual speech and gestures by sensors of mobile devices.
@article{Ryumin2024s23042284, author = {, Dmitry Ryumin and Ivanko, Denis and , Elena Ryumina}, title = {{Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices}}, journal = {Sensors}, volume = {23}, number = {4}, article-number = {2284}, year = {2023}, issn = {1424-8220}, doi = {10.3390/s23042284}, url = {https://www.mdpi.com/1424-8220/23/4/2284}, keywords = {Audio-Visual Speech Recognition, Model-Level Fusion, Lip-Reading, Gesture Recognition, Spatio-Temporal Features, Dimensionality Reduction Technique, Computer Vision}, dimensions = {true}, } - Multimodal Personality Traits Assessment (MuPTA) Corpus: The Impact of Spontaneous and Read SpeechIn Proceedings of the ISCA International Conference INTERSPEECH, 2023
Automatic personality traits assessment (PTA) provides high-level, intelligible predictive inputs for subsequent critical downstream tasks, such as job interview recommendations and mental healthcare monitoring. In this work, we introduce a novel Multimodal Personality Traits Assessment (MuPTA) corpus. Our MuPTA corpus is unique in that it contains both spontaneous and read speech collected in the midly-resourced Russian language. We present a novel audio-visual approach for PTA that is used in order to set up baseline results on this corpus. We further analyze the impact of both spontaneous and read speech types on the PTA predictive performance. We find that for the audio modality, the PTA predictive performances on short signals are almost equal regardless of the speech type, while PTA using video modality is more accurate with spontaneous speech compared to read one regardless of the signal length.
@inproceedings{ryumina23_interspeech, author = {Ryumina, Elena and Ryumin, Dmitry and Markitantov, Maxim and Kaya, Heysem and Karpov, Alexey}, title = {{Multimodal Personality Traits Assessment (MuPTA) Corpus: The Impact of Spontaneous and Read Speech}}, booktitle = {Proceedings of the ISCA International Conference INTERSPEECH}, year = {2023}, pages = {4049--4053}, doi = {10.21437/Interspeech.2023-1686}, url = {https://www.isca-archive.org/interspeech_2023/ryumina23_interspeech.html}, keywords = {Audio-Visual Resources, Data Annotation, Multimodal Paralinguistics, Personality Computing, Big Five Traits}, dimensions = {true}, } - DAVIS: Driver’s Audio-Visual Speech RecognitionIn Proceedings of the ISCA International Conference INTERSPEECH, 2022
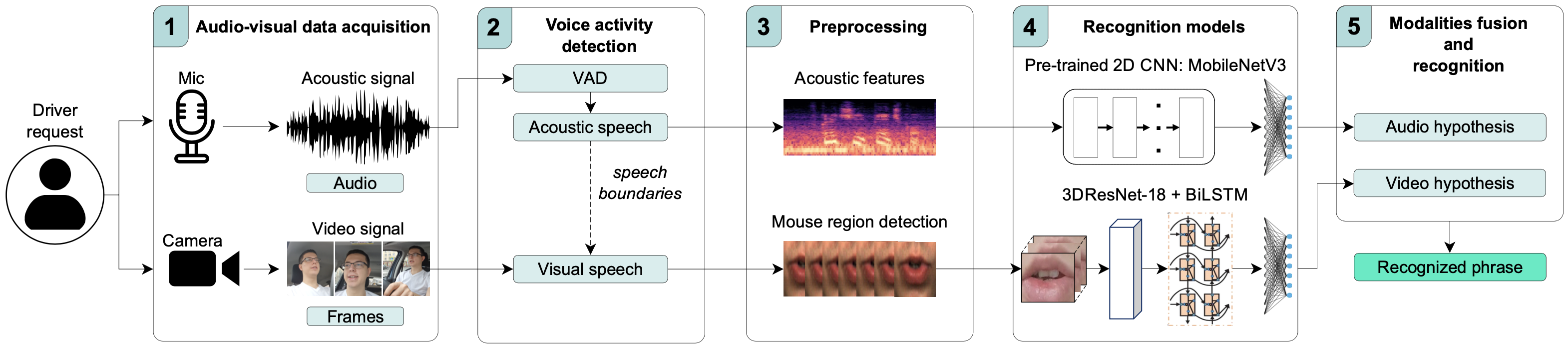
DAVIS is a driver’s audio-visual assistive system intended to improve accuracy and robustness of speech recognition of the most frequent drivers’ requests in natural driving conditions. Since speech recognition in driving condition is highly challenging due to acoustic noises, active head turns, pose variation, distance to recording devices, lightning conditions, etc. We rely on multimodal information and use both automatic lip-reading system for visual stream and ASR for audio stream processing. We have trained audio and video models on own RUSAVIC dataset containing in-the-wild audio and video recordings of 20 drivers. The recognition application comprises a graphical user interface and modules for audio and video signal acquisition, analysis, and recognition. The obtained results demonstrate rather high performance of DAVIS and also the fundamental possibility of recognizing speech commands by using video modality, even in such difficult natural conditions as driving.
@inproceedings{ivanko22_interspeech, author = {Ivanko, Denis and Ryumin, Dmitry and Kashevnik, Alexey and Axyonov, Alexandr and Kitenko, Andrey and Lashkov, Igor and Karpov, Alexey}, title = {{DAVIS: Driver’s Audio-Visual Speech Recognition}}, booktitle = {Proceedings of the ISCA International Conference INTERSPEECH}, year = {2022}, pages = {1141--1142}, url = {https://www.isca-archive.org/interspeech_2022/ivanko22_interspeech.html}, keywords = {Audio-Visual Speech Recognition, Driver Assistance System, Human-Computer Interaction}, dimensions = {true}, } - Biometric Russian Audio-Visual Extended MASKS (BRAVE-MASKS) Corpus: Multimodal Mask Type Recognition TaskIn Proceedings of the ISCA International Conference INTERSPEECH, 2022
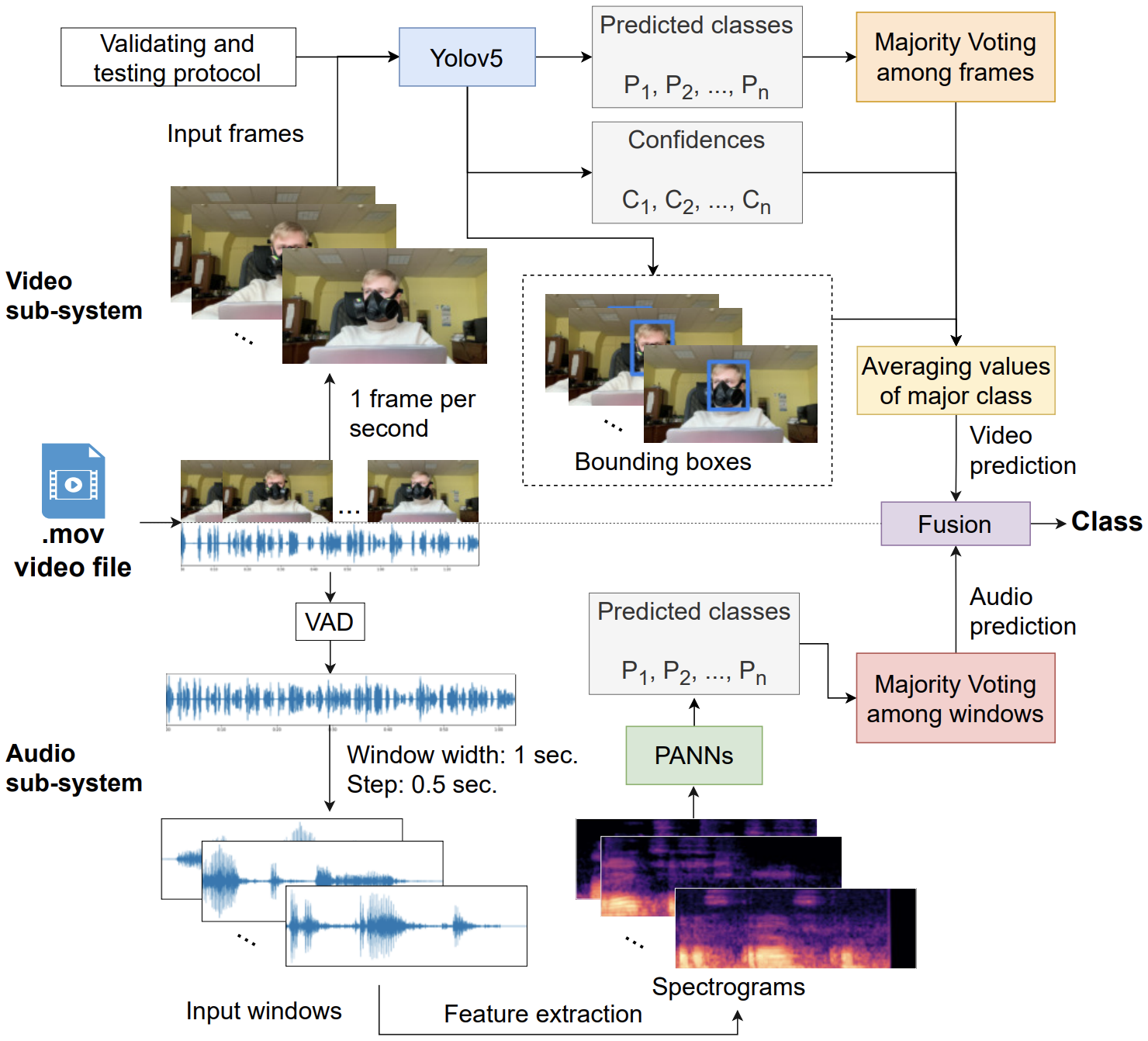
In this paper, we present a new multimodal corpus called Biometric Russian Audio-Visual Extended MASKS (BRAVE-MASKS), which is designed to analyze voice and facial characteristics of persons wearing various masks, as well as to develop automatic systems for bimodal verification and identification of speakers. In particular, we tackle the multimodal mask type recognition task (6 classes). As a result, audio, visual and multimodal systems were developed, which showed UAR of 54.83%, 72.02% and 82.01%, respectively, on the Test set. These performances are the baseline for the BRAVE-MASKS corpus to compare the follow-up approaches with the proposed systems.
@inproceedings{markitantov22_interspeech, author = {Markitantov, Maxim and Ryumina, Elena and Ryumin, Dmitry and Karpov, Alexey}, title = {{Biometric Russian Audio-Visual Extended MASKS (BRAVE-MASKS) Corpus: Multimodal Mask Type Recognition Task}}, booktitle = {Proceedings of the ISCA International Conference INTERSPEECH}, year = {2022}, pages = {1756--1760}, doi = {10.21437/Interspeech.2022-10240}, url = {https://www.isca-archive.org/interspeech_2022/markitantov22_interspeech.html}, keywords = {Mask Type Recognition, Face Masks Detection, Computational Paralinguistics, Corpora Annotation, Data Augmentation, Machine Learning, COVID-19}, dimensions = {true}, } - MIDriveSafely: Multimodal Interaction for Drive SafelyIn Proceedings of the International Conference on Multimodal Interaction (ICMI), Bengaluru, India, 2022
In this paper, we present a novel multimodal interaction application to help car drivers and increase their road safety. MIDriveSafely is a mobile application that provides the following functions: (1) detect dangerous situations based on video information from a smartphone front-facing camera, such as drowsiness/sleepiness, phone usage while driving, eating, smoking, unfastened seat belt, etc.; gives a feedback to the driver (2) provide entertainment (e.g. rock-paper-scissors game, based on automatic speech recognition), (3) provide voice control capabilities to navigation/multimedia systems of a smartphone (potentially vehicle systems such as lighting conditions/climate control). Speech recognition in driving conditions is highly challenging due to acoustic noises, active head turns, pose variations, distance to recording devices, etc. MIDriveSafely incorporates driver’s audio-visual speech recognition (DAVIS) system and uses it for multimodal interaction. Along with this, the original DriveSafely system is used for dangerous state detection. MIDriveSafely improves upon existing driver monitoring applications using multimodal (mainly audio-visual) information. MIDriveSafely motivates people to drive in a safer manner by providing the feedback to the drivers and by creating a fun user experience.
@inproceedings{ivanko22_icmi, author = {Ivanko, Denis and Kashevnik, Alexey and Ryumin, Dmitry and Kitenko, Andrey and Axyonov, Alexandr and Lashkov, Igor and Karpov, Alexey}, title = {{MIDriveSafely: Multimodal Interaction for Drive Safely}}, year = {2022}, booktitle = {Proceedings of the International Conference on Multimodal Interaction (ICMI)}, pages = {733--735}, numpages = {3}, isbn = {9781450393904}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, location = {Bengaluru, India}, url = {https://doi.org/10.1145/3536221.3557037}, doi = {10.1145/3536221.3557037}, keywords = {Driver Monitoring, Mobile Multimodal Systems, Multimodal Interaction}, dimensions = {true}, } - Visual Speech Recognition in a Driver Assistance SystemIn Proceedings of the European Signal Processing Conference (EUSIPCO), 2022
Visual speech recognition or automated lip-reading is a field of growing attention. Video data proved its usefulness in multimodal speech recognition, especially when acoustic data is heavily noised or even inaccessible. In this paper, we present a novel method for visual speech recognition. We benchmark it on the famous LRW lip-reading dataset by outperforming the existing approaches. After a comprehensive evaluation, we adapt the developed method and test it on the collected RUSAVIC corpus we recorded in-the-wild for vehicle driver. The results obtained demonstrate not only the high performance of the proposed method, but also the fundamental possibility of recognizing speech only by using video modality, even in such difficult natural conditions as driving.
@inproceedings{ivanko22_eusipco, author = {Ivanko, Denis and Ryumin, Dmitry and Kashevnik, Alexey and Axyonov, Alexandr and Karpov, Alexey}, title = {{Visual Speech Recognition in a Driver Assistance System}}, year = {2022}, booktitle = {Proceedings of the European Signal Processing Conference (EUSIPCO)}, pages = {1131--1135}, url = {https://ieeexplore.ieee.org/document/9909819}, doi = {10.23919/EUSIPCO55093.2022.9909819}, keywords = {Visualization, Europe, Speech Recognition, Benchmark Testing, Signal Processing,Acoustics, Speech Processing, Visual Speech Recognition, Automated Lip-Reading, End-to-End, Speech Recognition, Computer Vision}, dimensions = {true}, } - RUSAVIC Corpus: Russian Audio-Visual Speech in CarsIn Proceedings of the Language Resources and Evaluation Conference (LREC), 2022
We present a new audio-visual speech corpus (RUSAVIC) recorded in a car environment and designed for noise-robust speech recognition. Our goal was to produce a speech corpus which is natural (recorded in real driving conditions), controlled (providing different SNR levels by windows open/closed, moving/parked vehicle, etc.), and adequate size (the amount of data is enough to train state-of-the-art NN approaches). We focus on the problem of audio-visual speech recognition: with the use of automated lip-reading to improve the performance of audio-based speech recognition in the presence of severe acoustic noise caused by road traffic. We also describe the equipment and procedures used to create RUSAVIC corpus. Data are collected in a synchronous way through several smartphones located at different angles and equipped with FullHD video camera and microphone. The corpus includes the recordings of 20 drivers with minimum of 10 recording sessions for each. Besides providing a detailed description of the dataset and its collection pipeline, we evaluate several popular audio and visual speech recognition methods and present a set of baseline recognition results. At the moment RUSAVIC is a unique audio-visual corpus for the Russian language that is recorded in-the-wild condition and we make it publicly available.
@inproceedings{ivanko2022lrec, author = {Ivanko, Denis and Axyonov, Alexandr and Ryumin, Dmitry and Kashevnik, Alexey and Karpov, Alexey}, title = {{RUSAVIC Corpus: Russian Audio-Visual Speech in Cars}}, year = {2022}, booktitle = {Proceedings of the Language Resources and Evaluation Conference (LREC)}, pages = {1555--1559}, address = {Marseille, France}, publisher = {European Language Resources Association}, url = {https://aclanthology.org/2022.lrec-1.166}, keywords = {Audio-Visual Corpus, Automatic Speech Recognition, Data Collection, Automated Lip-Reading, Driver Monitoring}, dimensions = {true}, } - Multimodal Corpus Design for Audio-Visual Speech Recognition in Vehicle CabinIEEE Access, 2021
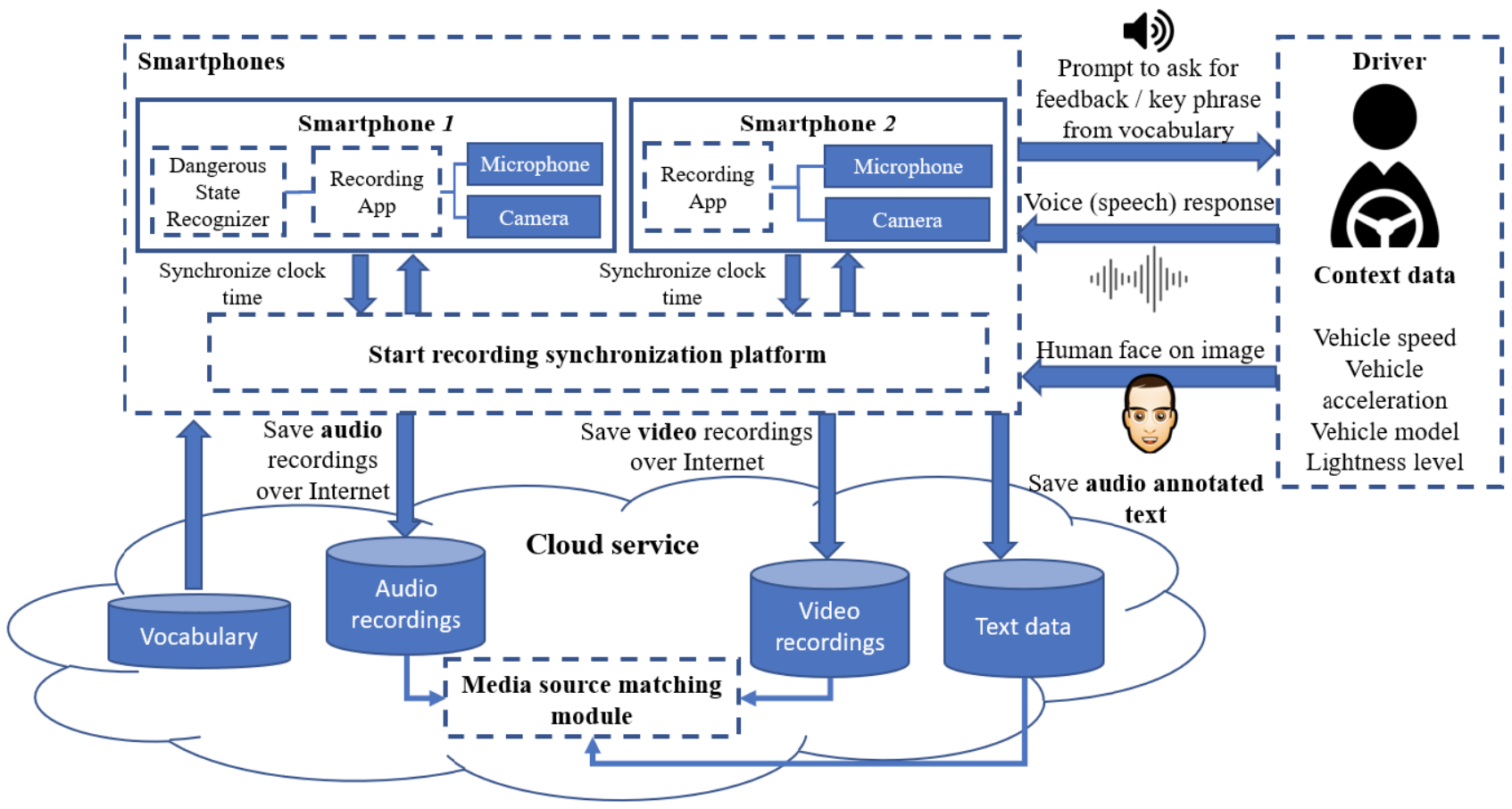
This paper introduces a new methodology aimed at comfort for the driver in-the-wild multimodal corpus creation for audio-visual speech recognition in driver monitoring systems. The presented methodology is universal and can be used for corpus recording for different languages. We present an analysis of speech recognition systems and voice interfaces for driver monitoring systems based on the analysis of both audio and video data. Multimodal speech recognition allows using audio data when video data are useless (e.g. at nighttime), as well as applying video data in acoustically noisy conditions (e.g., at highways). Our methodology identifies the main steps and requirements for multimodal corpus designing, including the development of a new framework for audio-visual corpus creation. We identify the main research questions related to the speech corpus creation task and discuss them in detail in this paper. We also consider some main cases of usage that require speech recognition in a vehicle cabin for interaction with a driver monitoring system. We also consider other important use cases when the system detects dangerous states of driver’s drowsiness and starts a question-answer game to prevent dangerous situations. At the end based on the proposed methodology, we developed a mobile application that allows us to record a corpus for the Russian language. We created RUSAVIC corpus using the developed mobile application that at the moment a unique audiovisual corpus for the Russian language that is recorded in-the-wild condition.
@article{Kashevnik2021_9364986, author = {Kashevnik, Alexey and Lashkov, Igor and Axyonov, Alexandr and Ivanko, Denis and Ryumin, Dmitry and Kolchin, Artem and Karpov, Alexey}, title = {{Multimodal Corpus Design for Audio-Visual Speech Recognition in Vehicle Cabin}}, journal = {IEEE Access}, volume = {9}, year = {2021}, pages = {34986--35003}, issn = {2169-3536}, doi = {10.1109/ACCESS.2021.3062752}, url = {https://ieeexplore.ieee.org/document/9364986}, keywords = {Vehicles, Speech Recognition, Smart Phones, Monitoring, Sensors, Vocabulary, Task Analysis, Driver Monitoring, Automatic Speech Recognition, Multimodal Corpus, Human–Computer Interaction}, dimensions = {true}, } - TheRuSLan: Database of Russian Sign LanguageIn Proceedings of the Language Resources and Evaluation Conference (LREC), 2020
In this paper, a new Russian sign language multimedia database TheRuSLan is presented. The database includes lexical units (single words and phrases) from Russian sign language within one subject area, namely, “food products at the supermarket”, and was collected using MS Kinect 2.0 device including both FullHD video and the depth map modes, which provides new opportunities for the lexicographical description of the Russian sign language vocabulary and enhances research in the field of automatic gesture recognition. Russian sign language has an official status in Russia, and over 120,000 deaf people in Russia and its neighboring countries use it as their first language. Russian sign language has no writing system, is poorly described and belongs to the low-resource languages. The authors formulate the basic principles of annotation of sign words, based on the collected data, and reveal the content of the collected database. In the future, the database will be expanded and comprise more lexical units. The database is explicitly made for the task of creating an automatic system for Russian sign language recognition.
@inproceedings{ivanko2022lred, author = {Kagirov, Ildar and Ivanko, Denis and Ryumin, Dmitry and Axyonov, Alexandr and Karpov, Alexey}, title = {{TheRuSLan: Database of Russian Sign Language}}, year = {2020}, booktitle = {Proceedings of the Language Resources and Evaluation Conference (LREC)}, pages = {6079--6085}, address = {Marseille, France}, publisher = {European Language Resources Association}, url = {https://aclanthology.org/2020.lrec-1.746}, keywords = {Russian Sign Language, Low Resourced Languages, Corpora Annotation, Image Recognition, Machine Learning}, dimensions = {true}, }